
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- python #pandas #data_preprocessing #data_process
- 특정값지우기
- version_error
- mnist
- AI #RNN #LSTM #LSTMP #인공지능 #언어학습 #순차학습
- AI #Inductive_Bias #Relational_inductive_bias
- MachineLearning
- fashionmnist
- pandas #python #date #datetime
- pandas #python #excel #판다스 #파이썬 #엑셀저장 #xlsxwriter
- aiohttp
- 파이썬
- tf.where
- 시계열데이터
- Github
- TensorFlow
- 선형회귀
- SQL #python #MySQL #PostgreSQL
- tensorflow #tensorflow-gpu #python #ubuntu #텐서플로우
- pandas #ewma #python #지수이동가중평균 #파이썬 #판다스 #ema #ewm
- git
- 판다스 #Pandas #DataFrame #Statistics #통계 #파이썬 #Python #Resample
- REST_API
- Asyncio
- Python
- 깃
- ngrok
- 비동기모듈
- SQL #PostgreSQL
- 깃허브
Archives
- Today
- Total
린스토리
[Pandas] EWMA 적용하기 본문
EWMA (Exponentially Weighted Moving Average) _ 지수가중평균
시간순서대로 나열되어 있는 데이터에 활용되며, 현재를 기준으로 오래된 값엔 낮은 가중치를 부여하고, 최근 값은 높게 부여하여 평균값을 도출하는 것
시계열 데이터를 다루다가 현재와 가까운 값이 더 중요함을 알려주고 싶어 고민하다가,
EWMA를 적용한 데이터로 가공하자는 생각이 들었다.
이를 Pandas에서 api로 제공하여 손쉽게 사용할 수 있는 방법을 소개하고자 한다. (자세한건 여기)

내가 EWMA를 적용한 방식은 다음과 같다.

이 수식을 위 api를 활용해 적용하면,
import pandas as pd
df = pd.DataFrame({'test': [540, 320, 680, 120, 960, 450]})
df['test_ema'] = round(df['test'].ewm(alpha=0.07, adjust=False).mean(), 0)결과는 다음과 같다.
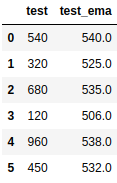
이 방식은 가중치가 일정하다. 만약 가중치 또한 시간에 따라 다르게 주고 싶다면 "adjust=True"로 변경하면 되고, 이 값이 default이다. 적용하게 되면 결과는 다음과 같이 나온다. 적용된 수식도 같이 첨부한다.
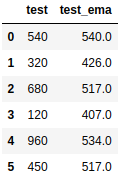
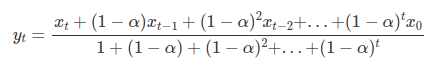
자세한 사용 방식은 공식 홈페이지를 보면 설명되어있다.
EWMA를 적용하기 위해 알고리즘으로 짜서 적용했었는데 이렇게 간단하게 api로 제공되니 코드도 짧아지고
여러모로 pandas의 기능이 고맙다. 앞으로 더 더 알아봐야지!!
'Python > Pandas' 카테고리의 다른 글
| [Pandas] Excel로 저장하기 (시트 여러개로 나눠서 저장하기) (0) | 2022.06.29 |
|---|---|
| [Pandas] 월별/주별/일별 데이터 통계내기 (Resample) (0) | 2022.06.28 |
| [Pandas] 날짜 생성하기 & 연산하기 (0) | 2022.06.19 |
| [Pandas] 조건 해당 값 변경 (0) | 2022.06.18 |
| [Pandas] DataFrame 생성 (0) | 2022.06.17 |
'Python/Pandas' Related Articles
more




Comments